Prompt Caching Explained: Improving Speed and Cost Efficiency in Large Language Models
- Jayant Upadhyaya
- Feb 10
- 6 min read

Large language models (LLMs) have become foundational components of modern software systems, powering applications ranging from customer support chatbots to document analysis tools and developer assistants.
As usage increases, so do concerns around latency, scalability, and cost. One of the most effective techniques for addressing these concerns is prompt caching.
Prompt caching is often misunderstood or conflated with traditional response caching. In reality, it operates at a fundamentally different level of the LLM processing pipeline.
When implemented correctly, prompt caching can significantly reduce inference time and operational cost, especially for applications that reuse large prompt components such as system instructions, long documents, or structured examples.
This article provides a detailed, technical explanation of prompt caching, how it works internally, when it is useful, how it differs from output caching, and how to structure prompts to maximize its effectiveness.
What Prompt Caching Is Not
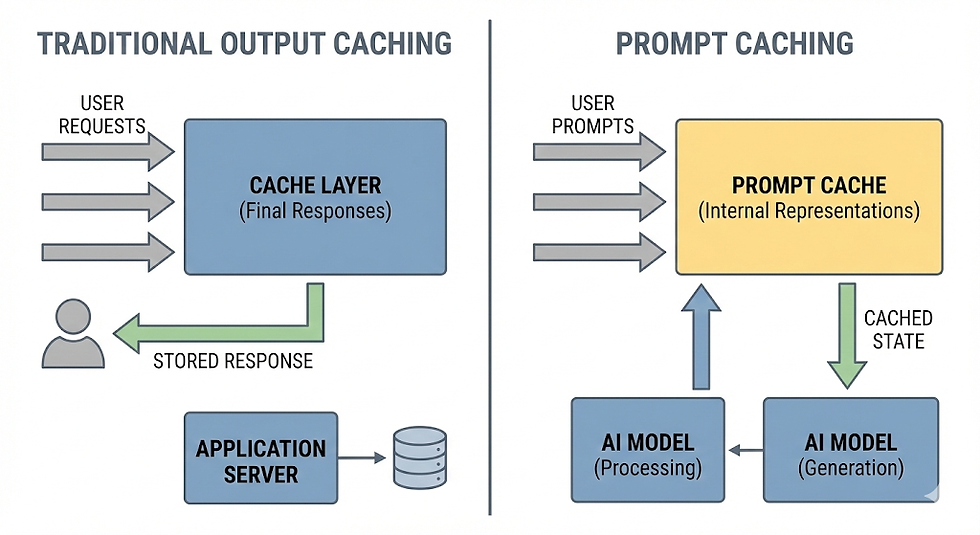
Before explaining prompt caching, it is important to clarify what it is not.
Prompt caching is not output caching.
Output Caching Explained
In traditional software systems, output caching works by storing the result of a computation so that it can be reused if the same request is made again. For example:
A user submits a SQL query to a database.
The database processes the query and returns a result.
That result is stored in a cache.
If another user submits the same query shortly afterward, the system retrieves the stored result instead of re-running the query.
This approach works well for deterministic systems where the same input always produces the same output.
Why Output Caching Is Different for LLMs
While output caching can technically be applied to LLMs, it has limitations:
LLM outputs are often non-deterministic unless temperature and randomness are tightly controlled.
Slight changes in prompts can invalidate cached responses.
Different users may require different formatting, tone, or personalization.
Cached outputs can become stale or contextually inappropriate.
Prompt caching addresses a different problem entirely. Instead of caching the final response, it caches intermediate computations performed by the model before it begins generating output.
How Large Language Models Process Prompts
To understand prompt caching, it is necessary to understand what happens internally when an LLM receives a prompt.
When a prompt is submitted to a transformer-based LLM, the process typically consists of two main phases:
Pre-fill phase
Token generation phase
The Pre-fill Phase
During the pre-fill phase:
The model reads the entire input prompt token by token.
At every transformer layer, the model computes key-value (KV) pairs for each token.
These KV pairs represent the model’s internal contextual understanding of the prompt:
How tokens relate to one another
What information is important
Which patterns or instructions should influence the output
This phase is computationally expensive because:
KV pairs must be computed across all transformer layers.
Long prompts with thousands of tokens require millions of mathematical operations.
No output tokens can be generated until this phase completes.
The Token Generation Phase
Once the pre-fill phase is complete:
The model begins generating output tokens one at a time.
Each new token uses the cached KV pairs from the pre-fill phase.
Generation is comparatively faster than pre-fill.
Prompt caching targets the pre-fill phase, not the output generation phase.
What Prompt Caching Actually Does
Prompt caching stores the pre-computed KV pairs generated during the pre-fill phase.
When a new request is received:
If the beginning of the prompt matches a previously cached prompt prefix,
The model can reuse the cached KV pairs instead of recomputing them,
The model only processes the new or changed tokens that appear after the cached prefix.
This results in:
Reduced latency
Lower compute usage
Lower cost per request
Why Prompt Caching Matters for Long Prompts

For short prompts, prompt caching provides little benefit.
For example:
“What is the capital of France?”
“Explain recursion in simple terms.”
These prompts contain very few tokens, and the pre-fill cost is minimal.
Prompt caching becomes valuable when prompts contain large static components.
Such as:
Long documents (contracts, manuals, research papers)
Extensive system instructions
Few-shot examples
Tool and function definitions
Conversation history
Example: Document-Based Prompting
Consider a prompt structure like this:
A 50-page technical manual
A system instruction defining how the model should behave
A user request asking for a summary
In this case:
The model must compute KV pairs for thousands of tokens before generating output.
This pre-fill cost dominates the total request time.
With prompt caching:
The KV pairs for the document and instructions are cached.
On subsequent requests:
The same document is reused
Only the new question is processed
The model skips recomputing the expensive pre-fill for the document
This can lead to dramatic performance improvements.
Common Use Cases for Prompt Caching
1. System Prompts
System prompts are one of the most common and effective caching targets.
System prompts typically include:
Role definitions (e.g., “You are a customer support assistant”)
Behavioral rules
Output formatting guidelines
Safety constraints
These instructions are often identical across all requests in an application. Caching them avoids redundant computation on every request.
2. Large Documents in Context
Prompt caching is particularly effective when working with:
Legal contracts
Product manuals
Academic papers
Policy documents
Internal knowledge bases
If users ask multiple questions about the same document, caching allows the document to be processed once and reused many times.
3. Few-Shot Examples
Few-shot prompting involves providing example inputs and outputs to guide model behavior. These examples are usually static and repeated across requests, making them ideal candidates for caching.
4. Tool and Function Definitions
Applications that use function calling or tool invocation often include structured schemas or definitions in the prompt. These definitions rarely change and can be cached effectively.
5. Conversation History
In some architectures, conversation history can be cached, particularly when early parts of the conversation remain unchanged across turns.
How Prompt Caching Works: Prefix Matching

Prompt caching relies on a technique known as prefix matching.
Prefix Matching Explained
The caching system compares incoming prompts token by token, starting from the beginning.
As long as tokens match a cached prompt exactly, cached KV pairs can be reused.
When the system encounters the first token that differs, caching stops.
All tokens after that point are processed normally.
Why Prompt Structure Matters
Because caching depends on prefix matching, prompt structure is critical.
Recommended Structure
To maximize cache hits:
Place static content first
System instructions
Documents
Examples
Place dynamic content last
User questions
Variable inputs
Poor Structure Example
If the prompt begins with a user question and places static content afterward:
Any change in the question invalidates the cache immediately.
The entire prompt must be reprocessed.
Optimal Structure Example
If static content comes first and the user question comes last:
The cached prefix remains valid across requests.
Only the new question is processed.
Token Thresholds and Cache Lifetimes
Minimum Token Requirements
Prompt caching typically requires a minimum prompt length to be effective.
Many systems require at least 1,024 tokens before caching is triggered.
Below this threshold, cache management overhead may exceed performance gains.
Cache Expiration
Prompt caches are not permanent:
Most caches are cleared after 5 to 10 minutes
Some systems allow cache lifetimes up to 24 hours
Cache eviction policies ensure memory efficiency and data freshness
Automatic vs Explicit Prompt Caching
Automatic Prompt Caching
Some LLM providers automatically cache prompt prefixes when conditions are met.
This requires:
Proper prompt structure
Repeated identical prefixes
Sufficient token length
Explicit Prompt Caching
Other providers require developers to explicitly specify which parts of a prompt should be cached through API parameters or annotations.
This approach offers greater control but requires careful implementation.
Cost and Latency Benefits

When used correctly, prompt caching can provide:
Significant reductions in request latency
Lower inference costs
Higher throughput for concurrent users
Improved user experience in interactive applications
These benefits are most pronounced in applications with large, reusable prompt components.
When Prompt Caching Is Not Useful
Prompt caching may offer limited or no benefit when:
Prompts are short
Prompts are entirely dynamic
Each request uses unique context
The overhead of cache management outweighs compute savings
In such cases, standard inference may be sufficient.
Summary
Prompt caching is a powerful optimization technique for large language models that focuses on caching the internal contextual representations of prompts rather than final outputs.
Key takeaways:
Prompt caching targets the pre-fill phase of LLM inference.
It caches KV pairs computed from prompt prefixes.
It is most effective for long, reusable prompt components.
Prompt structure is critical to achieving cache hits.
Proper use can significantly reduce latency and cost.
As LLM-based systems continue to scale, prompt caching will remain a foundational technique for building efficient, production-grade AI applications.



Comments